

1.ajax是什么?
全称是 asynchronous javascript and xml,是已有技术的组合,主要用来实现客户端与服务器端的异步通信效果(无需重新加载整个网页的情况下),实现页面的局部刷新。
通过在后台与服务器进行少量数据交换,ajax 可以使网页实现异步更新,用于创建快速动态网页。
早期的浏览器并不能原生支持 ajax,可以使用隐藏帧(iframe)方式变相实现异步效果,后来的浏览器提供了对 ajax 的原生支持。
2. ajax的工作原理
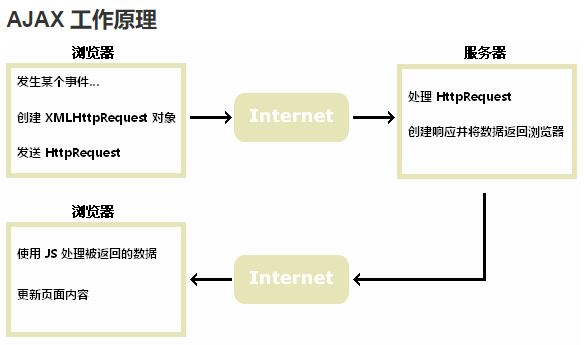
使用 ajax 原生方式发送请求主要通过 xmlhttprequest(ie7+、firefox、chrome、safari 以及opera) 、activexobject(ie5 和 ie6)对象实现异步通信效果。
创建xmlhttprequest对象:
var xhr;
if (window.xmlhttprequest)
{
// ie7+, firefox, chrome, opera, safari 浏览器执行代码
xhr=new xmlhttprequest();
}
else
{
// ie6, ie5 浏览器执行代码
xhr=new activexobject("microsoft.xmlhttp");
}
向服务器发送请求:使用 xmlhttprequest 对象的 open() 和 send() 方法
//通过 get 方法发送信息,请向 url 添加信息
xhr.open("get","/try/ajax/demo_get2.php?fname=henry&lname=ford",true);
xhr.send();
//像 html 表单那样 post 数据,使用 setrequestheader() 来添加 http 头
xhr.open("post","/try/ajax/demo_post2.php",true);
xhr.setrequestheader("content-type","application/x-www-form-urlencoded");
xhr.send("fname=henry&lname=ford");
//当使用 async=true 时,需规定在响应处于 onreadystatechange 事件中的就绪状态时执行的函数
xhr.onreadystatechange=function()
{
if (xhr.readystate==4 && xhr.status==200)
{
document.getelementbyid("mydiv").innerhtml=xhr.responsetext;
}
}
xhr.open("get","/try/ajax/ajax_info.txt",true);
xhr.send();
//当您使用 async=false 时,把代码放到 send() 语句后面即可,不推荐使用
xhr.open("get","/try/ajax/ajax_info.txt",false);
xhr.send();
document.getelementbyid("mydiv").innerhtml=xhr.responsetext;
使用get还是post?
与 post 相比,get 更简单也更快,并且在大部分情况下都能用。
与 post 相比,get 更简单也更快,并且在大部分情况下都能用。
然而,在以下情况中,请使用 post 请求:
无法使用缓存文件(更新服务器上的文件或数据库)
向服务器发送大量数据(post 没有数据量限制)
发送包含未知字符的用户输入时,post 比 get 更稳定也更可靠
//来自服务器的响应并非 xml,使用 responsetext 属性,返回字符串形式的响应
document.getelementbyid("mydiv").innerhtml=xhr.responsetext;
//来自服务器的响应是 xml,而且需要作为 xml 对象进行解析,使用 responsexml 属性,请求 cd_catalog.xml 文件,并解析响应
xmldoc=xhr.responsexml;
txt="";
x=xmldoc.getelementsbytagname("artist");
for (i=0;i<x.length;i++)
{
txt=txt + x[i].childnodes[0].nodevalue + "<br>";
}
document.getelementbyid("mydiv").innerhtml=txt;
onreadystatechange事件:当请求被发送到服务器时,我们需要执行一些基于响应的任务。每当 readystate 改变时,就会触发 onreadystatechange 事件。
//当 readystate 等于 4 且状态为 200 时,表示响应已就绪
xhr.onreadystatechange=function()
{
if (xhr.readystate==4 && xhr.status==200)
{
document.getelementbyid("mydiv").innerhtml=xhr.responsetext;
}
}
//如果存在多个 ajax 任务,那么应该为创建 xmlhttprequest 对象编写一个标准的函数,并为每个 ajax 任务调用该函数。该函数调用应该包含 url 以及发生 onreadystatechange 事件时执行的任务(每次调用可能不尽相同)
function myfunction()
{
loadxmldoc("/try/ajax/ajax_info.txt",function()
{
if (xmlhttp.readystate==4 && xmlhttp.status==200)
{
document.getelementbyid("mydiv").innerhtml=xmlhttp.responsetext;
}
});
}
xhr.readystate的值及解释:
0:请求未初始化(还没有调用 open())。
1:请求已经建立,但是还没有发送(还没有调用 send())。
2:请求已发送,正在处理中(通常现在可以从响应中获取内容头)。
3:请求在处理中;通常响应中已有部分数据可用了,但是服务器还没有完成响应的生成。
4:响应已完成;您可以获取并使用服务器的响应了。
xhr.status的值及解释:
100——客户必须继续发出请求
101——客户要求服务器根据请求转换http协议版本
200——交易成功
201——提示知道新文件的url
202——接受和处理、但处理未完成
203——返回信息不确定或不完整
204——请求收到,但返回信息为空
205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件
206——服务器已经完成了部分用户的get请求
300——请求的资源可在多处得到
301——删除请求数据
302——在其他地址发现了请求数据
303——建议客户访问其他url或访问方式
304——客户端已经执行了get,但文件未变化
305——请求的资源必须从服务器指定的地址得到
306——前一版本http中使用的代码,现行版本中不再使用
307——申明请求的资源临时性删除
400——错误请求,如语法错误
401——请求授权失败
402——保留有效chargeto头响应
403——请求不允许
404——没有发现文件、查询或url
405——用户在request-line字段定义的方法不允许
406——根据用户发送的accept拖,请求资源不可访问
407——类似401,用户必须首先在代理服务器上得到授权
408——客户端没有在用户指定的饿时间内完成请求
409——对当前资源状态,请求不能完成
410——服务器上不再有此资源且无进一步的参考地址
411——服务器拒绝用户定义的content-length属性请求
412——一个或多个请求头字段在当前请求中错误
413——请求的资源大于服务器允许的大小
414——请求的资源url长于服务器允许的长度
415——请求资源不支持请求项目格式
416——请求中包含range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含if-range请求头字段
417——服务器不满足请求expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求
500——服务器产生内部错误
501——服务器不支持请求的函数
502——服务器暂时不可用,有时是为了防止发生系统过载
503——服务器过载或暂停维修
504——关口过载,服务器使用另一个关口或服务来响应用户,等待时间设定值较长
505——服务器不支持或拒绝支请求头中指定的http版本
1xx:信息响应类,表示接收到请求并且继续处理
2xx:处理成功响应类,表示动作被成功接收、理解和接受
3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理
4xx:客户端错误,客户请求包含语法错误或者是不能正确执行
5xx:服务端错误,服务器不能正确执行一个正确的请求
3. ajax的优缺点
优点:1.无刷新更新数据:在不刷新整个页面的情况下维持与服务器通信
2.异步与服务器通信:使用异步的方式与服务器通信,不打断用户的操作
3.前端与后端负载均衡:将一些后端的工作移到前端,减少服务器与带宽的负担
4.基于规范被广泛支持:不需要下载浏览器插件或者小程序,但需要客户允许javascript在浏览器上执行。
5.界面与应用分离:ajax使得界面与应用分离,也就是数据与呈现分离
缺点: 1.ajax不支持back与history功能,即对浏览器机制的破坏:在动态更新页面的情况下,用户无法回到前一页的页面状态,因为浏览器仅能记忆历史纪录中的静态页面
2.安全问题:ajax技术给用户带来很好的用户体验的同时也对it企业带来了新的安全威胁,ajax技术就如同对企业数据建立了一个直接通道。这使得开发者在不经意间会暴露比以前更多的数据和服务器逻辑。ajax的逻辑可以对客户端的安全扫描技术隐藏起来,允许黑客从远端服务器上建立新的攻击。还有ajax也难以避免一些已知的安全弱点,诸如跨站点脚步攻击、sql注入攻击和基于credentials的安全漏洞等。
3.对搜索引擎支持较弱:如果使用不当,ajax会增大网络数据的流量,从而降低整个系统的性能。解决的办法:可以先用服务器渲染。
4.破坏程序的异常处理机制
5.违背url与资源定位的初衷
6.不能很好地支持移动设备
7.客户端肥大,太多客户段代码造成开发上的成本
4.应用场景
1.动态加载数据,按需取得数据。【树形菜单、联动菜单.../省市联动】
2.改善用户体验。【输入内容前提示、带进度条文件上传...】
3.电子商务应用。【购物车、邮件订阅...】
4.访问第三方服务。【访问搜索服务、rss阅读器】
5.数据的布局刷新
不适用于搜索,基本的导航,替换大量的文本,部分简单的表单
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持硕编程。
 学习AJAX
学习AJAX