

Ajax请求超时与网络异常处理图文详解
别用ie浏览器!!!
问题
当浏览器请求超时或者网络异常的时候,我们程序需要做出什么处理和反应呢?
ps:代码我会在后面贴出来,思路最重要
# 请求超时 首先在==express==逻辑上是这样子写的
// 模拟请求超时
app.all("/delay", (request, response) => {
response.setheader('access-control-allow-origin', '*');
response.setheader('access-control-allow-headers', '*');
settimeout(() => {
response.send('接收成功:模拟请求超时');
}, 3000);
})
前端的请求

一开始没有加请求时间的设置,是可以输出结果的

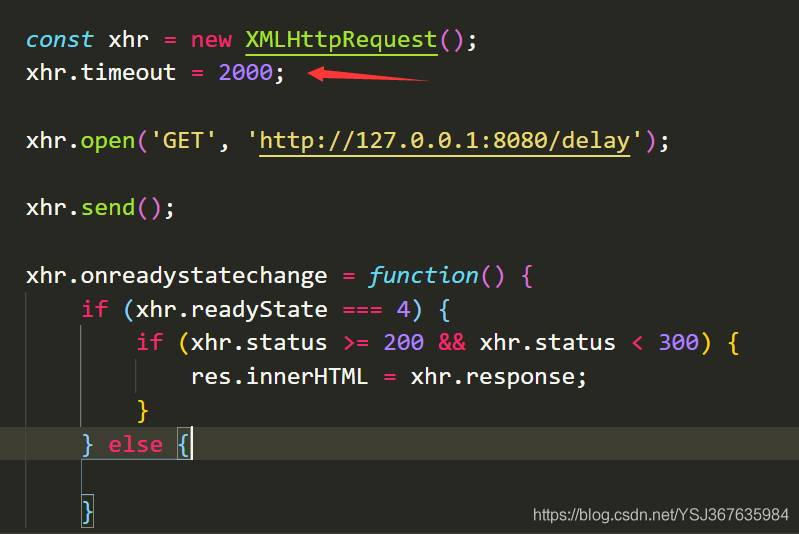
那么现在呢,我们需要为请求加上一个限制时间,超过这个限制时间,浏览器就会认为此时请求超时了。如下加上
保存代码,然后到浏览器刷新,打开控制台
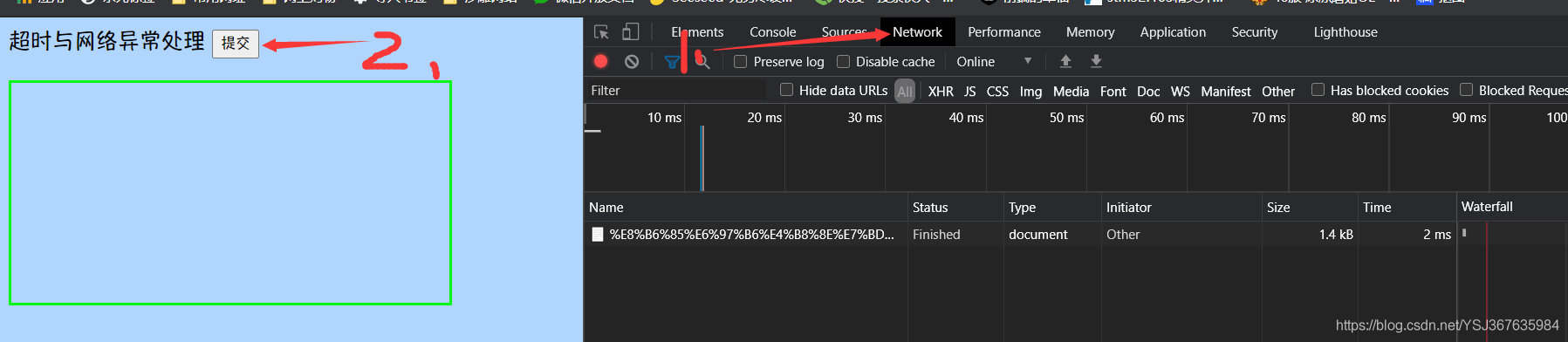
选择network,然后点击按钮,观察network的请求状态
首先一开始是pending状态(请求中)
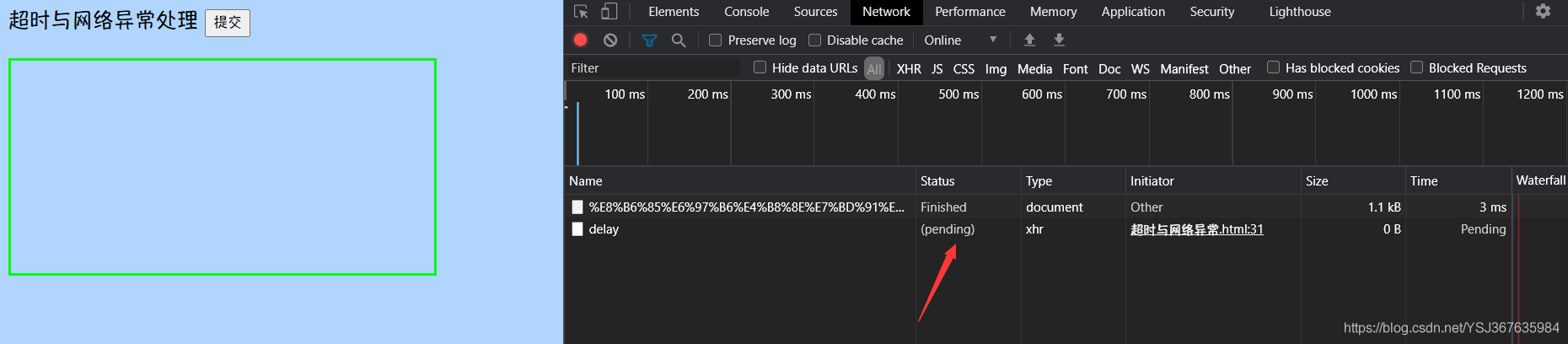
超过了请求的阈值(2s),此时显示请求被取消了,显示cancel状态,而不是finish

但是在实际业务中,你不可能让每个用户打开控制台看请求有没有超时吧,所以我们可以加一个请求超时回调来完成信息弹窗提醒

我们刷新运行,发现此时就有一个弹窗提示了
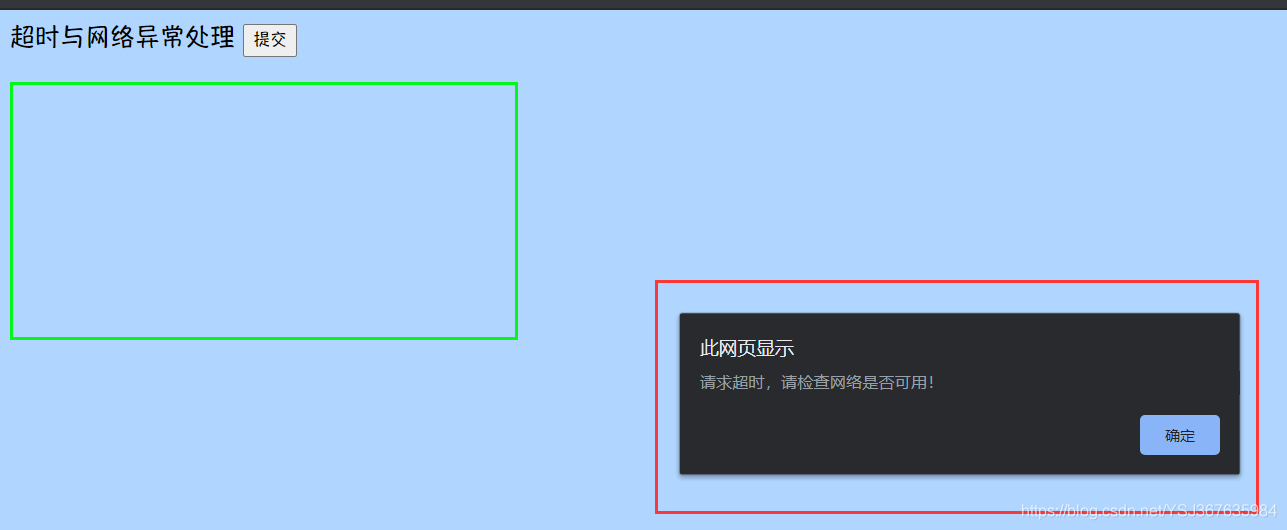
那么,请求超时就演示到这来
网络异常
现在来看看网络异常我们需要怎么处理,那么网络异常在前端js里面也是有回调函数的,如下
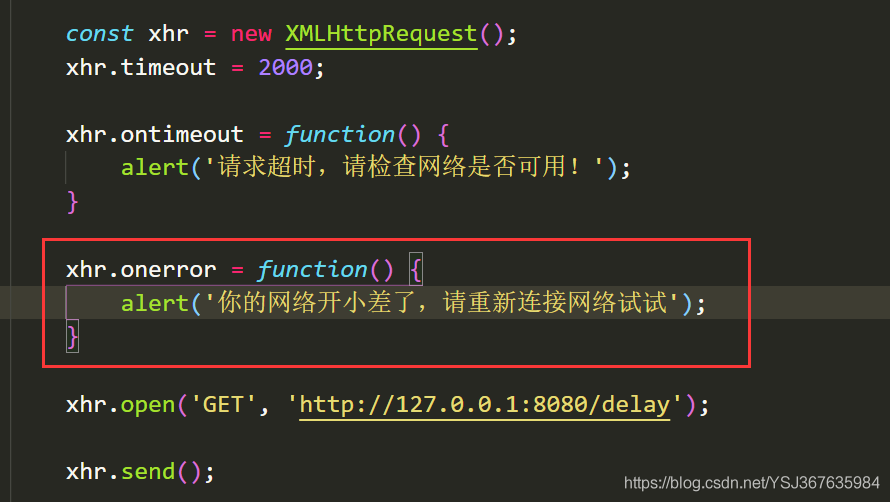
然后,我们通过浏览器的控制台模拟离线状态
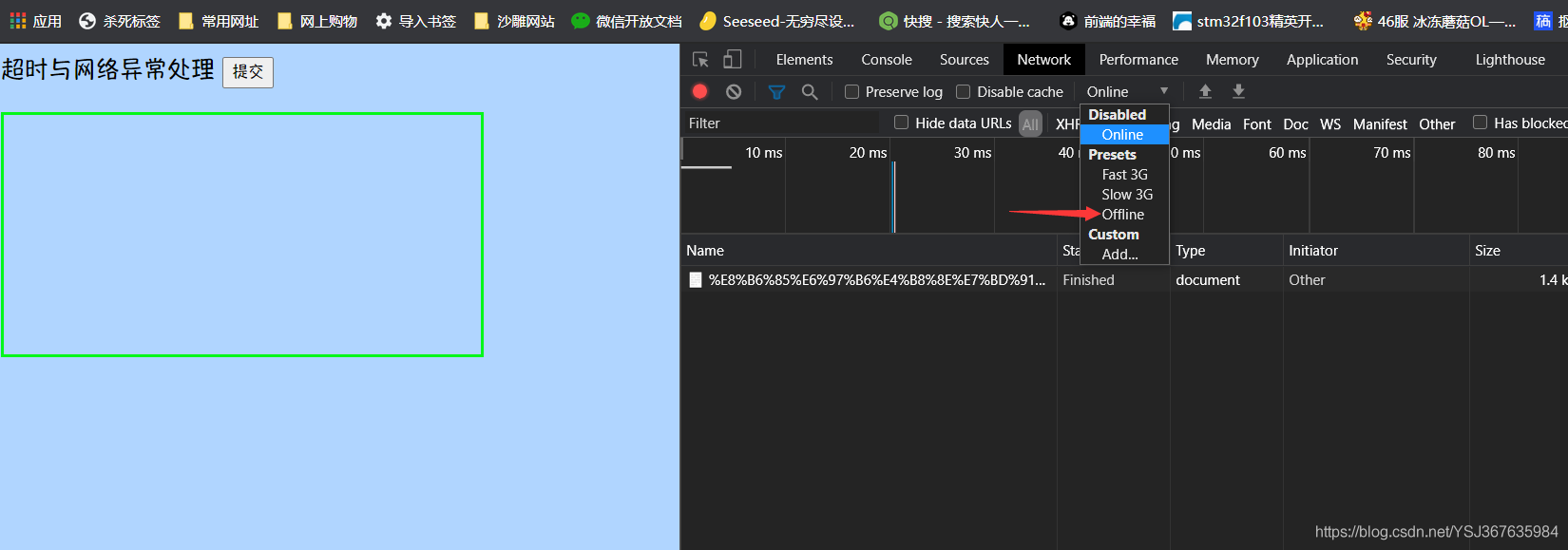
然后,我们点击按钮查看效果

莫得问题!
代码
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<titile>超时与网络异常处理</titile>
<style>
#content {
width: 400px;
height: 200px;
border: 1px solid rgb(4, 247, 25);
border-width: 3px;
margin: 20px 0 20px 0;
}
</style>
</head>
<body>
<button type="button">提交</button>
<div id="content"></div>
<script>
const btn = document.getelementsbytagname('button')[0];
const res = document.getelementbyid('content');
btn.onclick = function() {
const xhr = new xmlhttprequest();
xhr.timeout = 2000;
xhr.ontimeout = function() {
alert('请求超时,请检查网络是否可用!');
}
xhr.onerror = function() {
alert('你的网络开小差了,请重新连接网络试试');
}
xhr.open('get', 'http://127.0.0.1:8080/delay');
xhr.send();
xhr.onreadystatechange = function() {
if (xhr.readystate === 4) {
if (xhr.status >= 200 && xhr.status < 300) {
res.innerhtml = xhr.response;
}
} else {
}
}
};
</script>
</body>
</html>
const express = require("express");
const app = express();
// 模拟请求超时
app.all("/delay", (request, response) => {
response.setheader('access-control-allow-origin', '*');
response.setheader('access-control-allow-headers', '*');
settimeout(() => {
response.send('接收成功:模拟请求超时');
}, 3000);
})
app.listen(8080, () => {
console.log('正在监听8080端口');
});
总结
到此这篇关于ajax请求超时与网络异常处理的文章就介绍到这了,更多相关ajax请求超时内容请搜索硕编程以前的文章或继续浏览下面的相关文章希望大家以后多多支持硕编程!
 学习AJAX
学习AJAX