

oracle常见分析函数实例详解
1. 认识分析函数
1.1 什么是分析函数
分析函数是oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
1.2 分析函数和聚合函数的不同
普通的聚合函数用group by分组,每个分组返回一个统计值;而分析函数采用partition by 分组,并且每组每行都可以返回一个统计值。
1.3 分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by),排序(order by), 窗口(rows),他们的使用形式如下:
over(partition by xxx order by yyy rows between zzz) -- 例如在scott.emp表中:xxx为deptno, yyy为sal, -- zzz为unbounded preceding and unbounded following
分析函数的例子:
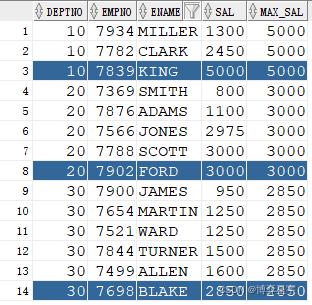
显示各部门员工的工资,并附带显示该部分的最高工资。
sql如下:
select deptno, empno, ename, sal, last_value(sal) over (partition by deptno order by sal rows between unbounded preceding and unbounded following) max_sal from emp;
结果为:
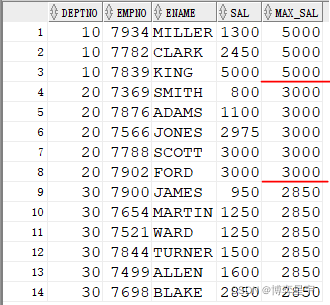
注: current row 表示当前行
unbounded preceding 表示第一行
unbounded following 表示最后一行
last_value(sal) 的结果与 order by sal 排序有关。如果排序为order by sal desc, 则最终的结果为分组排序后sal的最小值(分组排序后的最后一个值), 当deptno为10时,max_sal为1300。
2. 理解over()函数
2.1 两个order by 的执行机制
分析函数是在整个sql查询结束后(sql语句中的order by 的执行比较特殊)再进行的操作,也就是说sql语句中的order by也会影响分析函数的执行结果:
- 两者一致:如果sql语句中的order by 满足分析函数分析时要求的排序,那么sql语句中的排序将先执行,分析函数在分析时就不必再排序。
- 两者不一致:如果sql语句中的order by 不满足分析函数分析时要求的排序,那么sql语句中的排序将最后在分析函数分析结束后执行排序。
2.2 分析函数中的分组、排序、窗口
分析函数包含三个分析子句:分组(partition by)、排序(order by)、窗口(rows)。
窗口就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗口中的记录而不是整个分组中的记录。因此我们在想得到某个栏位的累计值时,我们需要把窗口指定到该分组中的第一行数据到当前行,如果你指定该窗口从该分组中的第一行到最后一行,那么该组中的每一个sum值都会一样,即整个组的总和。
窗口子句中我们经常用到指定第一行,当前行,最后一行这样的三个属性:
- 第一行是 unbounded preceding
- 当前行是 current row
- 最后一行是 unbounded following
窗口子句不能单独出现,必须有order by 子句时才能出现,如:
last_value(sal) over (partition by deptno order by sal rows between unbounded preceding and unbounded following )
以上示例指定窗口为整个分组.
而出现order by 子句的时候,不一定要有窗口子句,但效果会不一样,此时窗口默认是当前组的第一行到当前行!
sql语句为:
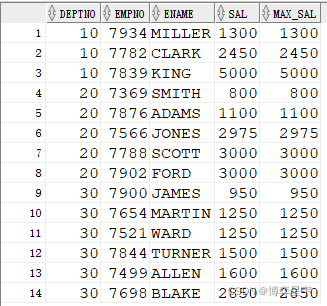
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal) max_sal from emp;
等价于
select deptno, empno, ename, sal,last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and current row) max_sal from emp;
结果如下图所示:
当省略窗口子句时:
- 如果存在order by, 则默认的窗口是 unbounded preceding and current row.
- 如果同时省略order by, 则默认的窗口是 unbounded preceding and unbounded following.
如果省略分组,则把全部记录当成一个组:
- 如果存在order by 则默认窗口是unbounded preceding and current row
- 如果这时省略order by 则窗口默认为 unbounded preceding and unbounded following
2.3 帮助理解over()的实例
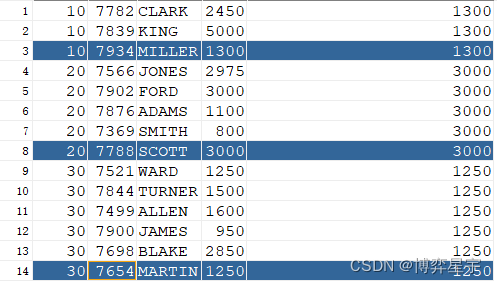
例1:关注点:sql无排序,over()排序子句省略
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno) from emp;
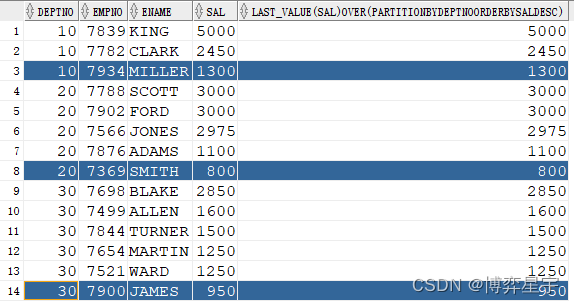
例2:关注点:sql无排序,over()排序子句有,窗口省略
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal desc) from emp;
例3:关注点:sql无排序,over()排序子句有,窗口也有,窗口特意强调全组数据
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following) max_sal from emp;
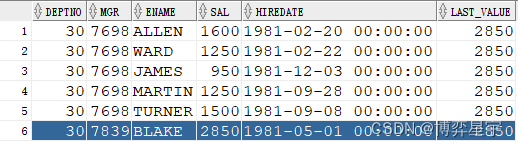
例4:关注点:sql有排序(正序),over() 排序子句无,先做sql排序再进行分析函数运算
select deptno, mgr, ename, sal, hiredate, last_value(sal) over(partition by deptno) last_value from emp where deptno=30 order by deptno, mgr;
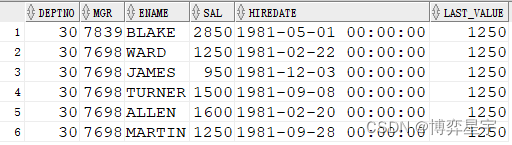
例5:关注点:sql有排序(倒序),over() 排序子句无,先做sql排序再进行分析函数运算
select deptno, mgr, ename, sal, hiredate, last_value(sal) over(partition by deptno) last_value from emp where deptno=30 order by deptno, mgr desc;
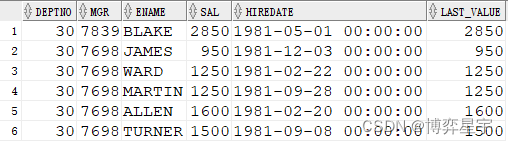
例6:关注点:sql有排序(倒序),over()排序子句有,窗口子句无,此时的运算是:sql先选数据但是不排序,而后排序子句先排序并进行分析函数处理(窗口默认为第一行到当前行),最后再进行sql排序
select deptno, mgr, ename, sal, hiredate, min(sal) over(partition by deptno order by sal)last_value from emp where deptno=30 order by deptno, mgr desc;

select deptno, mgr, ename, sal, hiredate, min(sal) over(partition by deptno order by sal desc) last_value from emp where deptno=30 order by deptno, mgr desc;
3. 常见分析函数
3.1 演示表和数据的生成
建表语句:
create table t( bill_month varchar2(12), area_code number, net_type varchar(2), local_fare number );
插入数据:
insert into t values('200405',5761,'g', 7393344.04);
insert into t values('200405',5761,'j', 5667089.85);
insert into t values('200405',5762,'g', 6315075.96);
insert into t values('200405',5762,'j', 6328716.15);
insert into t values('200405',5763,'g', 8861742.59);
insert into t values('200405',5763,'j', 7788036.32);
insert into t values('200405',5764,'g', 6028670.45);
insert into t values('200405',5764,'j', 6459121.49);
insert into t values('200405',5765,'g', 13156065.77);
insert into t values('200405',5765,'j', 11901671.70);
insert into t values('200406',5761,'g', 7614587.96);
insert into t values('200406',5761,'j', 5704343.05);
insert into t values('200406',5762,'g', 6556992.60);
insert into t values('200406',5762,'j', 6238068.05);
insert into t values('200406',5763,'g', 9130055.46);
insert into t values('200406',5763,'j', 7990460.25);
insert into t values('200406',5764,'g', 6387706.01);
insert into t values('200406',5764,'j', 6907481.66);
insert into t values('200406',5765,'g', 13562968.81);
insert into t values('200406',5765,'j', 12495492.50);
insert into t values('200407',5761,'g', 7987050.65);
insert into t values('200407',5761,'j', 5723215.28);
insert into t values('200407',5762,'g', 6833096.68);
insert into t values('200407',5762,'j', 6391201.44);
insert into t values('200407',5763,'g', 9410815.91);
insert into t values('200407',5763,'j', 8076677.41);
insert into t values('200407',5764,'g', 6456433.23);
insert into t values('200407',5764,'j', 6987660.53);
insert into t values('200407',5765,'g', 14000101.20);
insert into t values('200407',5765,'j', 12301780.20);
insert into t values('200408',5761,'g', 8085170.84);
insert into t values('200408',5761,'j', 6050611.37);
insert into t values('200408',5762,'g', 6854584.22);
insert into t values('200408',5762,'j', 6521884.50);
insert into t values('200408',5763,'g', 9468707.65);
insert into t values('200408',5763,'j', 8460049.43);
insert into t values('200408',5764,'g', 6587559.23);
insert into t values('200408',5764,'j', 7342135.86);
insert into t values('200408',5765,'g', 14450586.63);
insert into t values('200408',5765,'j', 12680052.38);
commit; 3.2 first_value()与last_value():求最值对应的其他属性
问题:取出每个月通话费最高和最低的两个地区
思路:先进行group by bill_month, area_code使用聚合函数sum()求解出by bill_month, area_code的local_fare总和, 即sum(local_fare),然后再运用分析函数进行求解每个月通话费用最高和最低的两个地区。
select bill_month, area_code, sum(local_fare) local_fare, first_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) firstval, last_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) lastval from t group by bill_month, area_code;

3.3 rank()、dense_rank()与row_number() 排序问题
演示数据再oracle自带的scott用户下
1.rank()值相同时排名相同,其后排名跳跃不连续
select * from ( select deptno, ename, sal, rank() over(partition by deptno order by sal desc) rw from emp ) where rw < 4;

2. dense_rank()值相同时排名相同,其后排名连续不跳跃
select * from ( select deptno, ename, sal, dense_rank() over(partition by deptno order by sal desc) rw from emp ) where rw <= 4;
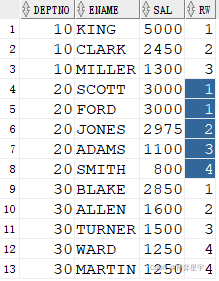
3. row_number()值相同时排名不相等,其后排名连续不跳跃
select * from ( select deptno, ename, sal, row_number() over(partition by deptno order by sal desc) rw from emp ) where rw <= 4;
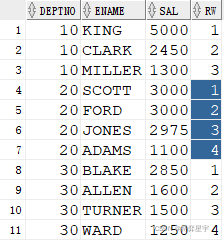
3.4 lag()与lead():求之前或之后的第n行
lag(arg1, arg2, arg3):
- arg1:是从其他行返回的表达式
- arg2:是希望检索的当前行分区的偏移量。是一个正的偏移量,是一个往回检索以前的行数目
- arg3:是在arg2表示的数目超出了分组的范围时返回的值
而lead()与lag()相反
select bill_month, area_code, local_fare cur_local_fare,
lag(local_fare, 1, 0) over(partition by area_code order by bill_month)
last_local_fare,
lead(local_fare, 1, 0) over(partition by area_code order by bill_month)
next_local_fare
from (select bill_month, area_code, sum(local_fare) local_fare
from t group by bill_month, area_code); 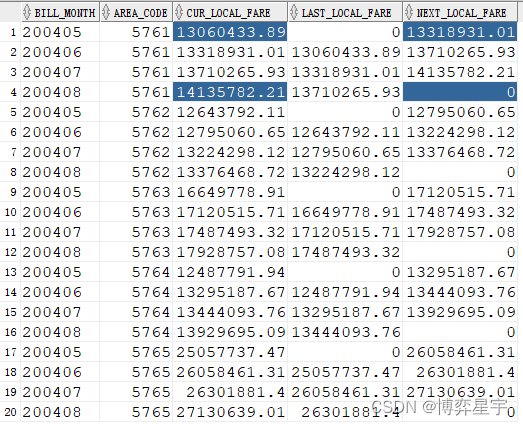
3.5 rollup()与cube():排列组合分组
group by rollup(a, b, c):
首先会对 (a, b, c) 进行group by,
然后再对 (a, b) 进行group by,
其后再对 (a) 进行group by,
最后对全表进行汇总操作。
group by cube(a, b, c):
则首先会对 (a, b, c) 进行group by,
然后依次是 (a, b), (a, c), (a), (b, c), (b), (c),
最后对全表进行汇总操作。
1.生成演示数据:
create table scott.tt as select * from dba_indexes;
2.普通group by 体验
select owner, index_type, status, count(*) from tt where owner like 'sy%' group by owner, index_type, status;
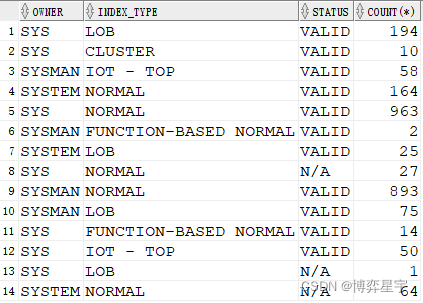
3. group by rollup(a, b, c):
首先会对 (a, b, c) 进行group by,
然后再对 (a, b) 进行group by,
其后再对 (a) 进行group by,
最后对全表进行汇总操作。
select owner, index_type, status, count(*) from tt where owner like 'sy%' group by rollup(owner, index_type, status);
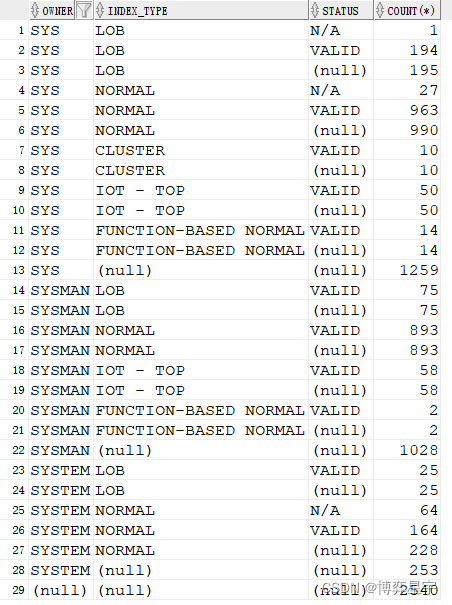
4. group by cube(a, b, c):
则首先会对 (a, b, c) 进行group by,
然后依次是 (a, b), (a, c), (a), (b, c), (b), (c),
最后对全表进行汇总操作。
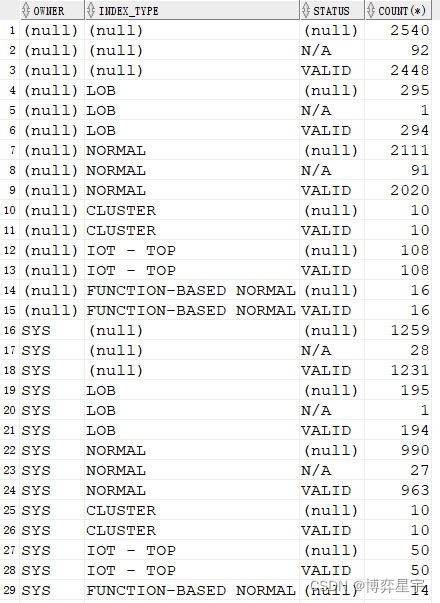
select owner, index_type, status, count(*) from tt where owner like 'sy%' group by cube(owner, index_type, status);
(只截取了部分图)
3.6 max()、min()、sum()与avg():求移动的最值、总和与平均值
问题:计算出各个地区连续3个月的通话费用的平均数(移动平均值)
select area_code, bill_month, local_fare,
sum(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_sum,
avg(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_avg,
max(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_max,
min(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_min
from (select bill_month, area_code, sum(local_fare) local_fare from t
group by area_code, bill_month); 
问题:求各地区按月份累加的通话费
select area_code, bill_month, local_fare, sum(local_fare) over(partition by area_code order by bill_month asc) last_sum_value from(select area_code, bill_month, sum(local_fare) local_fare from t group by area_code, bill_month) order by area_code, bill_month;

3.7 ratio_to_report():求百分比
问题:求各地区花费占各月花费的比例
select bill_month, area_code, sum(local_fare) local_fare, ratio_to_report(sum(local_fare)) over (partition by bill_month) as area_pct from t group by bill_month, area_code;
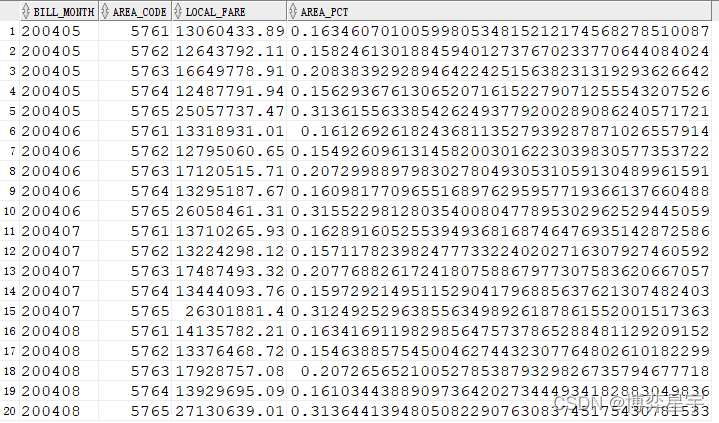
总结
关于oracle常见分析函数的文章就介绍至此,更多相关oracle分析函数内容请搜索硕编程以前的文章,希望以后支持硕编程!
- Oracle 外键创建
- Oracle 级联删除外键
- Oracle Compose()函数
- Oracle Convert()函数
- Oracle Dump()函数
- Memcached 教程
- Memcached set 命令
- Memcached replace 命令
- Memcached incr 与 decr 命令
- Memcached stats 命令
- Memcached flush_all 命令
- PHP 连接 Memcached 服务
- DB2表
- DB2数据库安全
- DB2 LDAP
- Oracle中的table()函数使用
- 关于ORA-04091异常的出现原因分析及解决方案
- 连接Oracle数据库失败(ORA-12514)故障排除全过程
- Oracle常见分析函数实例详解
- Oracle报错:ORA-28001:口令已失效解决办法
 其他数据库
其他数据库